selenium爬虫被检测到 该如何破
知乎上看到的讨论,感觉很受用,记录了一下:
源地址:selenium爬虫被检测到 该如何破? - 知乎 (zhihu.com)
推荐去源地址看
import time
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
browser = webdriver.Chrome()
browser.implicitly_wait(40)
browser.get("https://www.crunchbase.com/app/search/companies/")
time.sleep(60)
Pardon Our Interruption...
As you were browsing crunchbase accelerates innovation by bringing together data on companies and the people behind them. something about your browser made us think you were a bot. There are a few reasons this might happen:
- You're a power user moving through this website with super-human speed.
- You've disabled JavaScript in your web browser.
- A third-party browser plugin, such as Ghostery or NoScript, is preventing JavaScript from running. Additional information is available in this support article.
To request an unblock, please fill out the form below and we will review it as soon as possible.
该网站使用了http://distilnetworks.com的反爬服务.
23 个回答
谢邀。。。我刚用selenium+phanotomjs试了一下,发现返回结果和题主的一样。不得已使用了selenium+chrome/firefox,发现均出现这些问题。我觉得它的反爬策略不是根据爬虫的行为来判断的,因为使用爬虫打开网页它就已经把你认定为爬虫了,根本没给你展示你的行为的机会。依据我的经验,它是直接提取的浏览器驱动的指纹特征,比如常用的驱动有chromedriver,这种方式基本上我还没找到一个好的应对方式。为了验证我的想法,我选择了使用geckodriver(Releases · mozilla/geckodriver · GitHub)来驱动firefox(没有使用firefox自带的webdriver,因为自带的webdriver它已经被收集指纹了),第一次返回的结果的意思是:不能识别该浏览器。从这点可以看出它有一个可识别的指纹特征列表,不在次范围内的都不能访问,在此范围内的,只有是合法的(非webdriver驱动的)才能访问。另外,它一旦发现你用的webdriver驱动,那么它就会把你的IP暂时列入黑名单,这时候就算你手动输入网址都不能访问,但是过一段时间又可以访问了,我这边测试的情况就是这样。
以前我也做过类似的研究,可以看看我提的问题(怎么识别自动化的Web爬虫(比如采用selenium或者phantomjs)? - Python)。当时我们组做了两个解决方案,一个就是使用它未采集的webdriver来驱动浏览器,这里似乎不行,因为未采集的它都一律不给通过。另外一个方法就是读它的js源码了,然后挨着步骤调试,这种方法需要很深的js功底。
说了这么多,很惭愧我还是没有找到有效采集目标网站的方法15 条评论


本人之前在做X宝,X评,X团的爬虫项目时,均遇到了获取cookies这个重要的问题,而获取cookies的前提是实现用户登录,登陆的过程就不赘述了,相信大家都遇到了滑块,滚动条等反爬手段,(本人用webdriver破解),可大厂的技术团队还是给了我们一个更难解决的问题,就是通过js给webdriver请求响应错误信息。那我们的思考路线就是如何让这个js文件功能作废,本人使用的方法是通过 mitmproxy 蔽掉识别 webdriver 标识符的 js 文件。
首先下载mitproxy,pip安装方法:
pip install mitmproxy
基本使用方法:
- 给本机设置代理ip 127.0.0.1端口8001(为了让所有流量走mitmproxy)具体方法请百度。
2. 启动mitmproxy。
windows:
mitmdump -p 8001
Linux:
mitmproxy -p 8001
3. 打开chrome的开发者工具,找到目标网站是通过哪个js文件控制webdriver相应的, 如:
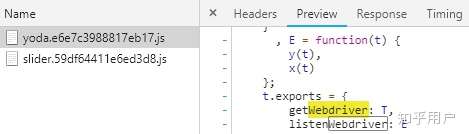
4. 开始写干扰脚本(DriverPass.py):
import re
from mitmproxy import ctx
def response(flow):
if '/js/yoda.' in flow.request.url:
for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate', '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped', '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium', '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate', 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc', '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert', '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo', '$cdc_asdjflasutopfhvcZLmcfl_' ]:
ctx.log.info('Remove "{}" from {}.'.format(
webdriver_key, flow.request.url
))
flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('t.webdriver', 'false')
flow.response.text = flow.response.text.replace('ChromeDriver', '')5. 退出刚才的mitmproxy状态,重新用命令行启动mitmproxy干扰脚本 监听8001端口的请求与响应。
mitmdump -s DriverPass.py -p 8001
6. 现在别管mitmproxy,启动webdriver 顺利获得cookies。
大功告成,点个赞再走。
个人经历,即使是使用Selenium调用ChromeDriver来打开网页,其还是与正常打开网页有区别的,有被识别的可能性。
因为在尝试登录阿里爸爸的某平台后台信息时,手动使用浏览器打开的网页登录的时候输入用户名和密码直接就登录进去了,而使用selenium操纵ChromeDriver打开的网页登录操作,不仅需要滑块验证,而且滑块验证还总是失败(手动拖鼠标滑块)。
区别以及被识别的原因是什么,目前还没有找到原因,可能是因为被识别到浏览器是使用自动测试工具进行的操作:
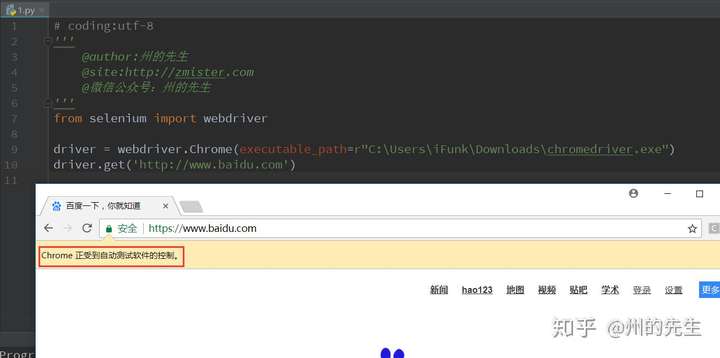
如何解决呢?一个方法是使用pyqt的qtwebengine组件,具体怎么实现,可以自己思考一下。
19 条评论
有没有解决办法了 大佬 我也是这个情况 解决不了
的确有,我今天用selenium也是过不了阿里滑块,真是无语了,求解决方案
 知乎用户2020-08-15
知乎用户2020-08-15qtwebengine 怎么实现,求方法?
- 我也想过用pyqt 封装浏览器来搞,都是基于webkit的反正
 知乎用户2018-05-16
知乎用户2018-05-16同求 有偿求
- 同求。
都一样了!要么你代码里面写上不打开浏览器窗口也行,都能爬到数据的.我一晚上把新浪上五大联赛六个赛季所有球队的出场阵型爬了个遍(都没加User-Agent和Cookie).回来对比一下数据,完全没问题(今晚继续爬其他的//手动滑稽).反正我就是把浏览器弹窗关了,弹出的CMD窗口关了,哈哈,眼不见心不烦.嘿嘿嘿
- 看我的文章
- 改了user-agent
请问各位大神,如何才能过去呢?
 知乎用户2018-03-27可以试试直接get
知乎用户2018-03-27可以试试直接get
- 我也是 用selenium就打不开 同个窗口手动就能点开
阿里的反爬搞的我真是没脾气了
selenium在运行的时候会暴露出一些预定义的Javascript变量(特征字符串),例如"window.navigator.webdriver",在非selenium环境下其值为undefined,而在selenium环境下,其值为true
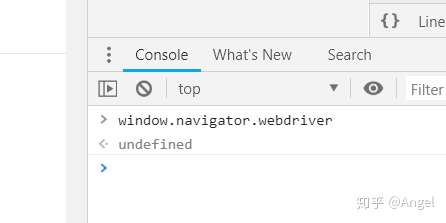
除此之外,还有一些其它的标志性字符串(不同的浏览器可能会有所不同):
- webdriver
- __driver_evaluate
- __webdriver_evaluate
- __selenium_evaluate
- __fxdriver_evaluate
- __driver_unwrapped
- __webdriver_unwrapped
- __selenium_unwrapped
- __fxdriver_unwrapped
- _Selenium_IDE_Recorder
- _selenium
- calledSelenium
- _WEBDRIVER_ELEM_CACHE
- ChromeDriverw
- driver-evaluate
- webdriver-evaluate
- selenium-evaluate
- webdriverCommand
- webdriver-evaluate-response
- __webdriverFunc
- __webdriver_script_fn
- __$webdriverAsyncExecutor
- __lastWatirAlert
- __lastWatirConfirm
- __lastWatirPrompt
- $chrome_asyncScriptInfo
- $cdc_asdjflasutopfhvcZLmcfl_
了解了这个特点之后,就可以在浏览器客户端JS中通过检测这些特征串来判断当前是否使用了selenium,并将检测结果附加到后续请求之中,这样服务端就能识别并拦截后续的请求。

可行的做法是通过mitmproxy类型代理工具,修改js文件,替换文件内所有变量关键词,或者将其不可执行,从而避免被识别。
2 条评论
爬虫要用一些调度策略,避免触发机器人识别程序。机器人识别程序有些很简单,比如,根据单位时间内访问的网页数量,有些比较复杂,比如根据访问的网页间关系,还有更复杂的根据监听网页上的事件。
反正要让爬虫的行为特别像真人,目前我重点是做行为建模,比如,我从GooSeeker爬虫6.x版本开始增加了一个开发者工具:录制真人浏览网页的事件,期望建立一个十分逼真的模型。在这个回答中有说明:直接用Charles抓包的信息, python 模拟登录网站的一点问题? - 华天清的回答
其实反爬就是提高爬虫成本,直到高到爬数据不划算为止。crunchbase和其它好多种企业信息有关的网站我都爬过,多用一些爬虫电脑,各自用不同的ADSL线路或者使用proxy轮换等,每爬一个网页随机歇一下等等。楼上其他方法都试过,我把最终的结果总结了下。
- 识别selenium,可以通过window.navigater.webdriver的属性值来识别,这种可以使用中间件拦截来改变这个值。
- 但是有的网站不仅仅是这。还会检测selenium里面一些特殊的js变量名,这种理论上也可以采用中间件来处理检测方法。
- 但是中的但是,还没完。开启selenium好像是开启了一个本地代理,所有的操作都是通过和代理通信来操作浏览器,包括find_element方法。也有的网站js能识别是否使用了这些方法。js是怎么知道selenium的准确代理地址和是否进行了通信,自己的js基础薄弱,还没搞懂。大牛阅及,望指正。
2 条评论
phantomjs 会被好些网站自动认作爬虫。因为正常人是不会用这个浏览器的……建议尝试直接上chrome 的 webdriver。使用方法和 phantomjs 完全一样。还可以实时方便的监控网页的爬取进程。之前做过一个爬取google的小项目,最后就是用chrome加随机延时防止被捉的。
PS:我简单测试了一下,用chrome是可以自动打开这个网站的。from selenium import webdriver
test_url = 'https://www.crunchbase.com/app/search/companies'
spider = webdriver.Chrome('C:/Program Files (x86)/Chromedriver/chromedriver.exe')
spider.get(test_url)PS:如果用了chrome还有问题,那应该就是爬虫策略太简单了,或者掉进蜜罐了,要仔细看源代码或者尝试降低爬取速度
stackoverflow上有个相同问题。链接在这里:
Can a website detect when you are using selenium with chromedriver?
高票答案说这种识别是通过辨认一些带有selenium特征的javascript预定义变量来实现的,且不同的浏览器所能暴露出来的特征不一样。那哥们也是用的chrome,他提出的解决方法是改掉这些变量的名称。他自己下了chromedriver的源码,把里面特征变量的名字改掉,然后重新编译,结果似乎是骗过了目标网站。但是他后面补充了一点:在此之前你最好不要被网站加入黑名单里,因为你的浏览器有自己独特的指纹可以被追踪。 更具体的讨论还得看原帖。
里面第二个回答还引用了一段 "Distil Networks" (题主提到的那个distilnetworks.com)CEO的话,提到了逆向工程和模式识别。他们似乎是通过多种技术来实现对机器人的识别,但是更多的细节并没有透露。
我对webdriver的实现细节并不清楚,之前一直觉得 手动打开浏览器 和 使用webdriver打开浏览器 应该没有差别,都是货真价实的浏览器嘛,但从现在这个情况看,在使用selenium时,浏览器的某些特征和手动打开时是不一样的。只要你用webdriver打开了浏览器,浏览目标网站时即便不对浏览器进行更多操作,也能被网站发现。就看这个网站是不是使用了这样的识别技术了。
不知题主找到解决方法没,感觉重新编译还是有点麻烦啊。今天也遇到这个问题,现在我只能先附上最上面的链接,如果后面解决了这个问题,我会把步骤补上供大家参考。要是题主已经解决了的话还请分享一下解决方法呀!
9 条评论
爬大众点评的时候,爬的量比较大,代码没多久就被封了,但是发现只有部分页面会检测爬虫,如果不是一定要爬的页面的话,可以改一下爬虫策略,只爬那些不检测的页面,这种页面一般也不是很需要sleep。
前段时间用selenium写了个去某网站解析抖音视频去水印 小工具,然后这几天突然不能用了,返回的提示是客户端浏览器异常,应该就是大神们说的什么特征码的问题了,我用selenium打开浏览器,自己手动操作一样不行。解决方法就是手动打开浏览器,然后用selenium控制这个浏览器跑程序。反正我的问题是这么解决的
21 条评论
我直接在程序里面写了个进程用so.system打开chrome,然后用driver接管。但是问题是,这样操作不能挂代理IP啊,操作多了就被封IP了。如何在手动打开之前给chrome加代理IP(非全局代理IP)?
- 手动打开,然后跑,怎么做的
言简意赅,解决了我的问题。感谢大神
- 赞
- 之前都是先selenium打开一个浏览器并输出id和url,输入密码进入其他页面后再接管这个浏览器。今天涨知识了!
我这样搞后,webdriver还是自己另外打开了一个浏览器
不知道
看了一些答案,并没有很好地解决楼主这个问题。正好这段时间也在研究这个方面的问题,有一些心得,就顺便来回答一波。
selenium爬虫被识别的原因很简单,就是因为浏览器中的window.navigator.webdriver属性被JS暴露了出来,而被服务器端所识别,触发了服务器的反爬策略,导致爬取失败。
比较简单的解决方法有两个:
- Chrome从v63版本开始添加了这一属性,那么我们就可以使用低于v63版本的Chrome来实现即可(v62.0.3202.62版本测试通过,当然也不要忘了将chromedriver换成对应的版本)。
- 使用google新推出的puppeteer,现在已经有对应的python版本pyppeteer,功能非常强大,绝对算得新一代爬虫利器,相信你去用了之后会爱上它的。API参考地址:
4 条评论
一般防爬的目的就两种:
1.防止资源被拉取,这种用心做了特别难爬
2.防止服务器被弄挂了,这种做个限速就OK了
发个JS给你,你浏览器多大,鼠标位置在哪里,点击验证拖动验证码要花多长时间点下去多久松开多久,包括光影特征,比如你是chrome模拟成firefox ua的根本没用人家清清楚楚,是不是人的行为特征一下子就知道了,webdrive是真实浏览器没错的,但是是不是人行为也可以获取的。
爬虫比较容易改的就是一些头部特征,比如UA什么的,这种抓个包就知道咋回事了,之所以可以抓取是因为人家没有花费这个精力去防爬,或者资源价值在那不值得这样搞
NikeLab x Kim Jones Tech Fleece Hoody (Hyper Pink Heather & Clear) 这个网站就获取不到
遇到同样问题,正在查资料。以下是查到的一些相关知识点
可以看这篇文章以及文内链接科普一些必要知识↓ 包括selenium如何被识别
可以用pyppeteer注入js脚本:
mitmproxy中间人攻击:

还可以使用google的cdp协议,预加载js,做一些简单的措施,例如,修改window.navigator.webdriver的值。
补充一下,除了webdriver,有一个叫ichrome的包也挺好用的,直接调用cdp。应该是比较新的项目。
我最近也遇到了这个问题,确实是Chromedriver打开地址会有有特征的Javascript变量

有个解决办法是使用中间人代理过滤掉特征字符串,使网站认为非Chromedriver。
3 条评论
1 条评论
- 知乎用户2019-03-30
某宝那个数据包比js好不到哪去mmp
如果上面链接挂了,还有一个Python爬虫防封杀方法集合,内容都是一样的,就是有时候CSDN抽了,就挂简书上了
2 条评论
 匿名用户 (提问者)2016-09-18好的。 已经修改。 谢谢
匿名用户 (提问者)2016-09-18好的。 已经修改。 谢谢 匿名用户 (作者) 回复匿名用户 (提问者)2016-09-18已经回复。
匿名用户 (作者) 回复匿名用户 (提问者)2016-09-18已经回复。




http://www.slideshare.net/SergeyShekyan/shekyan-zhang-owasp
这有俩链接是相关的。 希望对你们也有所帮助
webdriver这个我也没特别深入了解,还需要多多踩坑才弄得清楚啊
呜呜呜,大神们都没法解决的话,弃疗了……
早就是这样了
两种测试结果是一样的,都可以抓取。但是我没有大批量爬,这个网站需要账号才能翻页。
我用F12看了加载过程,加载这个页面有好大数量的GET和POST消息。我现在怀疑你是不是对cookie或者是redirect类操作处理的不够合理,忽略了一些应该处理的消息,被识别成了非真人操作。
但是,有一点我理解不了,根据我的理解,用python的driver话,比如,驱动Firefox,它驱动起来的是真正的Firefox,只是使用了不同的profile,从而与日常启动的Firefox进程是两个不同进程,但是他们运行的程序应该完全一样,按照我的理解,他们表现出来的指纹应该是一样的。不知道我理解的对不对
使用webdriver打开浏览器和人手动打开浏览器应该不是一样的吧,这个我不是很肯定,但是我确实是有这方面的一个经验,当时是我们项目组帮另外一个公司做测试,他们所做的一个方面就是提供反爬虫服务。情景是这样的,如果我自己手动点开浏览器输入网址,每次都可以请求成功,并且可以实现站内的链接跳转。如果是用selenium的话,firefox打开直接显示空白页,chrome打开的话只能采集到第一页(使用chrome可以采集到第一页,对方给我们的回答是chrome比较强大,还没做到完全禁止。),而跳转后也是空白页。即使是我设置profile和正常使用的时候一样,它还是这种情况。所以我断定有技术可以分辨出到底是用的驱动还是手动打开浏览器的,也就是说这两种打开方式表现的特征应该不同。
刚我去看了一下那个测试网址,很遗憾不能打开了,应该是我们做过测试后对方就撤销了,毕竟这个技术目前还没大规模普及。
webdriver启动的浏览器到底有什么区别,我也是凭观察做的判断,很多技术点我也没有探清楚,比如,webdriver怎样从浏览器窗口中把html文档导出来、怎样做动作,我不知道webdriver是怎样驱动的。
做反爬,还是有很多可利用的特征的。以前我主要做浏览器扩展,在原浏览器基础上增加爬虫功能,很隐蔽,但是现在所有浏览器不允许写C++扩展了。只要是从外部驱动或者自己的浏览器,就会留下很多可识别的特征